今天面試考白版題,整個頭腦轉不過來...就只好回家檢討一下問題了
1.寫出一個反轉字串的方法
2.一樣是反轉字串的方法,但不行使用迴圈的方式
這部分我分兩個...一個是我自己寫的,一個是看網路上比較簡易的==
2.1
2.2
然後需要檢討時間複雜度和空間複雜度的運算和StringBuffer...完全忘記了,這部分下次再補齊
2016年11月15日 星期二
補充知識
今天和一個朋友聊天,聊了很多知識東西,我想要把它記下來和補充
1. Override and overload的差別
2. IO dead lock 是什麼, 如何處理?
4. Clean code and dirty code
5. IPv4 Internal IP
6. Agile Scrum
override:子類別繼承父類別的函式,然後改寫其繼承的函式,但必須是函式名稱相同、參數型態個數相同,傳回型態相同。
overload:相同的函式名稱,但參數型態、參數個數、傳回型態只要任一個不同,就會呼叫不同的函數。
process的通常流程=要求資源->使用資源->釋放資源
而dead lock通常要滿足下面條件
a.Mutul exclusion:一個資源(Instances)一次只能被ㄧ 個process使用。
b.Hold and wait:當多個process發生mutul exclusion,然後尋求下一個資源時,都有process在 使用,造成一個等待資源動作出現。
c.No preemption:而資源又不能經過其他方法來釋放,只能依靠使用的process來自行處理。
d.Circular wait:就造成每個process都握有另一個process請求的資源,然後各自沒有釋放本身 持有的資源,造成一個循環出現。
那我們該如何處理
a.完全無視他...反正出現死結機率很低,大不了重開機或重開程式讓他重新來過就好了...
b.偵測死結發生,然後經由自己寫的程式邏輯來恢復運作。
c.使用一個protocol來預防或避免死結發生。
3.繼承、封裝、多型,如何用最普通的講話來解釋?
因為我只會實作,真的沒想過如何用普通的講話說出來,我這裡試著用我想法講出來
這裏我舉一個汽車工廠的例子
當母公司做了一個汽車模組出來分送給底下的子公司,然後子公司依照所待的國家區域,來做調整,例如是顏色問題、燈的明暗度、和左右邊駕駛問題,而這就是「子繼承父」的觀念了。
而封裝就像是避免存取一些你不想讓人知道的東西,舉個例子來說,每個汽車裡都有一個微電腦,而開發汽車微電腦的人,不想有人亂動裡面機密的設定,避免造成車禍事件發生,所以他們就只提供,供應微電腦的電源連接器、微電腦輸出設定到儀表板上,而微電腦就是被封裝的東西,而電源連接器和輸出設定就是提供微電腦的介面方法。
多型,我就在繼承的例子,再改一下,當母公司做了一個汽車模組設計圖,而這個汽車模組設計圖依照各個國家、地區、氣候、政治的不同,有不同的設計成品出來,而這些設計成品的原型是從「同一個名稱的汽車模組設計圖」出來的。
dirty code指的是讓人覺得很難看得懂的程式,有可能是重複宣告、同樣的程式碼、髒亂的排版、沒有註解...等等,而會造成這個原因有可能是自身實力不足或者是為圖方便之類,從而造成程式碼越來越髒、當越髒時Bug也會越多,因為當你看不懂時就會亂改參數或者是重新寫一個新的,而通常這都會造成下一個問題出現,因為你看不懂程式碼,無法全面觀察改變之後會造成什麼事情出現,而clean code就是除去這些問題所寫的完美程式碼,我這裡推薦兩個網址,這裡詳述一些dirty code的問題。
http://www.ithome.com.tw/node/83209
http://keystonegame.pixnet.net/blog/post/17243817-%E7%A8%8B%E5%BC%8F%E7%A2%BC%E5%A3%9E%E5%91%B3%E9%81%93(code-bad-smell)
參考資料:
http://sls.weco.net/node/21327
http://www.ithome.com.tw/node/83209
http://keystonegame.pixnet.net/blog/post/17243817-%E7%A8%8B%E5%BC%8F%E7%A2%BC%E5%A3%9E%E5%91%B3%E9%81%93(code-bad-smell)
https://toggl.com/developer-methods-infographic
2016年10月11日 星期二
C/C++ call by value, call by address, call by reference
標頭都加上
#include <iostream >
using namespace std ;
然後使用dev c++
==============================================
int main( )
{
int i=1;
cout << i <<endl; // print 1
}
==============================================
int main( )
{
int i=1;
cout << &i <<endl; // print i address
}
==============================================
int main( )
{
int i=1;
int &j=i; //讓j的位址指向i的位址( 兩個位址會一樣)
cout << j << endl; //print j values (That is i values)
cout << &j << endl; // print j address (That is i address)
}
==============================================
int main( )
{
int i=1;
int *k=&i; //讓k的變數參照i的位址( 兩個位址會不一樣)
cout << k << endl; // print k values => i address (所以k變數數值列印出來是i的位址)
cout << &k << endl; // print k address (是指k的位址, 不關變數i的事情)
cout << *k << endl; // print i address pointer values (指的是, k指標變數所參照i位址的數值)
}
=============================================
#include <
然後使用dev c++
==============================================
{
}
==============================================
{
}
==============================================
{
}
==============================================
{
}
=============================================
2016年10月7日 星期五
eclipse java project 應用於XAMPP MySQL
因為我是第一次用jdbc,所以就在這記錄一些事情
首先下載mysql-connector-java .
download
然後add external jars,
之後試著寫一段程式連接
會發現出現一個錯誤
ClassNotFoundException: java . lang . com . . jdbc .
是因為MYSQL 預設是不允許通過遠端存取資料庫
所以必須在mysql command下指令:
1.改表
use
select , ,
update
2.授權法
grant . mypassword
或者是特定主機才可以連線
grant . . mypassword
然後重開mysql,之後就能成功存取了
再來下面是實作結果
reference
https://blog.yslifes.com/archives/918
https://my.oschina.net/weiweiblog/blog/664373
首先下載mysql-connector-
然後add external jars
之後試著寫一段程式連接
會發現出現一個錯誤
ClassNotFoundException
是因為MYSQL 預設是不允許通過遠端存取資料庫
所以必須在mysql command下指令:
1.改表
2.授權法
或者是特定主機才可以連線
然後重開mysql,之後就能成功存取了
再來下面是實作結果
https://blog.yslifes.com/archives/918
https://my.oschina.net/weiweiblog/blog/664373
2016年9月30日 星期五
Java 關於ArrayList 深度複製
自從學會ArrayList泛型使用,我就開始愛上他來做陣列使用。
簡單的泛型使用類似下面code,第一段是簡單的int泛型,第二段是int[]的陣列。
然後ArrayList也能使用物件來當參數,例如下面:
ArrayList使用容易,也很好分辨
如果你要複製一樣的ArrayList,可以用以下的式子
但是,如果你是使用ArrayList<陣列 or 物件>,你就要特別小心了
例如下面
可以發現到當arrayList改變時,arrayListCopy數值也會跟著改變,是因為ArrayList是淺度複製,當參數是單純變數時(例:int, String, boolean),複製的arrayListCopy不會改變,但當參數是陣列 or 物件,ArrayList<int[]> arrayListCopy=new ArrayList<int[]>(arrayList); arrayListCopy 和 arrayList指向的是同一個記憶體位置,所以會造成某個ArrayList改變時,另一個就會跟著改變。
而如果要簡單解決這問題的話,只要做下面的方法就行了:
ArrayList<int[]> arrayListCopy=new ArrayList<int[]>(arrayList);
改成
for ( int [ ] copy: arrayList )
arrayListCopy . add( copy. clone( ));
簡單的泛型使用類似下面code,第一段是簡單的int泛型,第二段是int[]的陣列。
然後ArrayList也能使用物件來當參數,例如下面:
ArrayList使用容易,也很好分辨
如果你要複製一樣的ArrayList,可以用以下的式子
但是,如果你是使用ArrayList<陣列 or 物件>,你就要特別小心了
例如下面
可以發現到當arrayList改變時,arrayListCopy數值也會跟著改變,是因為ArrayList是淺度複製,當參數是單純變數時(例:int, String, boolean),複製的arrayListCopy不會改變,但當參數是陣列 or 物件,ArrayList<int[]> arrayListCopy=new ArrayList<int[]>(arrayList); arrayListCopy 和 arrayList指向的是同一個記憶體位置,所以會造成某個ArrayList改變時,另一個就會跟著改變。
而如果要簡單解決這問題的話,只要做下面的方法就行了:
ArrayList<int[]> arrayListCopy=new ArrayList<int[]>(arrayList);
改成
ArrayList<int[]> arrayListCopy=new ArrayList<int[]>();
{
}
一個一個陣列把他複製下來。
也可以使用 BeanUtils.cloneBean來把它複製。
2016年9月1日 星期四
Java使用Matlab封裝成的.jar檔(R2015b)
一開始必須要環境準備
1.設置Java JDK1.7X (不能使用JDK1.8以上的版本,會造成Error during packaging ,可以參考這篇文章)
2.設置環境變數(可以參考此文章來設置)

( 2) Classpath
( 3) Path










之後在程式碼加上幾行指令,呼叫.jar檔裡的CallFunction類別,建立出物件(建立實例物件需要花費1~2S時間,不知道為什麼,還沒詳細爬文),然後利用Object陣列變數接收所呼叫的值,這邊需要注意的是CallFunction.test(2,1),第一個參數是指回傳回來的參數個數,第二個是你要傳值給test方法計算的數值,如果你還有更多需要傳值的數值,就繼續寫在後面即可(但必須test方法裡也有符合的參數個數)
此外,你必須加上一個try catch接收Matlab jar有可能引發的錯誤訊息(如:MWException e)
最後你就能看到你的程式碼執行成功了,如下圖

1.設置Java JDK1.7X (不能使用JDK1.8以上的版本,會造成Error during packaging ,可以參考這篇文章)
2.設置環境變數(可以參考此文章來設置)
(1)JAVA_HOME (JDK的安裝位置,如C:\Program Files\Java\jdk1.7.0_79)
- 設置後,重啟matlab才有效果。
- 使用getenv JAVA_HOME在Matlab的Command Window中下指令,看看得到的返回職是否正確,如正確會出現以下對話。

- 添加matlabInstallRoot \toolbox\javabuilder\jar\javabuilder.jar
- 添加%JAVA_HOME%/bin/javac
此設置環境變數是參考此文章

之後點選Library Compiler,會出現以下圖示,然後在TYPE往下拉找到Java Package


然後,我們再回到Library Compiler步驟,我們在藍色筆跡那邊點進去,然後把test.m檔給新增進去

然後輸入Library Nam,我是輸入LibraryTest,之後輸入下方的ClassName,我是輸入CallFunction,這時候可以發現到,我的test.m的方法已經出現在Class Name的旁邊

之後按下右上方的Package等他封裝完成在你Settings所指定的目錄底下就行了

之後會出現檔案目錄出來,之後點選for_testing目錄,可以看到LibraryTest.jar在裡面了


最後我以Intellij IDEA 來展示如何使用封裝後的*.jar檔案
1.先開一個空專案,如下圖
1.先開一個空專案,如下圖

之後同時按下SHIFT+CTRL+ALT+S( window底下) 開啟Project structure

有個+號點進去,之後點資料夾找到你的.jar檔所在,新增進去,之後Apply
然後在點+號,再新增一個Matlab會使用到的.jar檔,此檔案在
matlabInstallRoot \toolbox\javabuilder\jar\javabuilder.jar
然後在點+號,再新增一個Matlab會使用到的.jar檔,此檔案在
之後在程式碼加上幾行指令,呼叫.jar檔裡的CallFunction類別,建立出物件(建立實例物件需要花費1~2S時間,不知道為什麼,還沒詳細爬文),然後利用Object陣列變數接收所呼叫的值,這邊需要注意的是CallFunction.test(2,1),第一個參數是指回傳回來的參數個數,第二個是你要傳值給test方法計算的數值,如果你還有更多需要傳值的數值,就繼續寫在後面即可(但必須test方法裡也有符合的參數個數)
此外,你必須加上一個try catch接收Matlab jar有可能引發的錯誤訊息(如:MWException e)
最後你就能看到你的程式碼執行成功了,如下圖

2016年6月29日 星期三
Java SocketServer的運用
最近實作簡單的SocketServer,可以互相多人通訊
先來講講 我實作的 Server Client 概念
我把SocketServer分為四個部分
第一部分initLayout(),我利用swing來繪製程式,主要是宣告一個panel,然後把繪圖元件都丟進去panel裡,再利用fame新增panel,在更新畫面(fame.ravalidate())
第二部分setIPAdrress(),利用InetAddress物件,把自身IP放入在LBIpAds.setText()。
第三部分initRequestListener(),把TFmsg TextField增加傾聽者(KeyListener),傾聽
TFmsgKeyListener物件,裡面主要功能是keyReleased(KeyEvent event),當按下按鈕放開時,會觸發這個功能。
第四部分是serverReceiver(),我宣告兩個變數ServerSocket和ExecutorService,ServerSocket放入自身接收Port,LISTEN_PORT=2525,而ExecutorService 則是接收當有ServerSocket回應(
serverSocket . , ( ) , (
我們來講解一下ServerReceiveThread部分,這是當有Client回應時,Server會專門創立一個Thread給它,一直傾聽有沒有訊息回來。而ServerRequestThread部分,則是Server想要發送訊息,或者是當有Client傳訊息到Serever再轉發給其他Client時,會使用的物件。
再來是SocketClient部分,也分為四個部分
前兩個部分和Server一樣,
第三部分是initSocketClient( String host, int port), 利用new Socket( host, port ) ;, 連線遠端的Server, 給他一個Thread執行傾聽遠端Server的訊息, 這部分和Server一樣。
而initRequestListener()部分,也是和Server一樣,傾聽鍵盤回應,然後發送給ClientRequestThread,讓他傳送到Server。
以下是程式碼,可以直接執行
先來講講 我實作的 Server Client 概念
我把SocketServer分為四個部分
第一部分initLayout(),我利用swing來繪製程式,主要是宣告一個panel,然後把繪圖元件都丟進去panel裡,再利用fame新增panel,在更新畫面(fame.ravalidate())
第二部分setIPAdrress(),利用InetAddress物件,把自身IP放入在LBIpAds.setText()。
第三部分initRequestListener(),把TFmsg TextField增加傾聽者(KeyListener),傾聽
TFmsgKeyListener物件,裡面主要功能是keyReleased(KeyEvent event),當按下按鈕放開時,會觸發這個功能。
第四部分是serverReceiver(),我宣告兩個變數ServerSocket和ExecutorService,ServerSocket放入自身接收Port,LISTEN_PORT=2525,而ExecutorService 則是接收當有ServerSocket回應(
我們來講解一下ServerReceiveThread部分,這是當有Client回應時,Server會專門創立一個Thread給它,一直傾聽有沒有訊息回來。而ServerRequestThread部分,則是Server想要發送訊息,或者是當有Client傳訊息到Serever再轉發給其他Client時,會使用的物件。
再來是SocketClient部分,也分為四個部分
前兩個部分和Server一樣,
第三部分是initSocketClient
而initRequestListener()部分,也是和Server一樣,傾聽鍵盤回應,然後發送給ClientRequestThread,讓他傳送到Server。
以下是程式碼,可以直接執行
2016年6月21日 星期二
字元與字串
講串流之前,先釐清字元與字串
字元
一個英文字母、數字、或其他符號,我們稱為字元,要表示成一個字元時,我們可以用一對單引號
e.gs.
而java中有一些特殊字元可以使用,通常用反斜線與一個字元作組合,我們稱之為 逸出序列(escape sequence),而反斜線又稱為逸出字元(escape character)
常見的逸出序列有以下:
1.\n 換行符號
2.\t 水平定位鍵
3.\r 歸位字元
4.\\ 列印反斜線
5.\" 列印雙引號
而電腦儲存字元的方式是以八位元整數( ) , ( , 以前常聽到的對應就是'a'=36 'A'=97
字串
字串顧名思義是一段文字,通常使用一對雙引號將一段文字夾起來,而英文字會佔1Byte,中文字佔2Bytes,而我們要判斷一段文字是否有中文則可以使用
String s="您好";
System.out.println((s.getBytes().length==s.length())?"無中文":"有中文");
利用Bytes總數和字串長度做比對。
字元
一個英文字母、數字、或其他符號,我們稱為字元,要表示成一個字元時,我們可以用一對單引號
而java中有一些特殊字元可以使用,通常用反斜線與一個字元作組合,我們稱之為 逸出序列(escape sequence),而反斜線又稱為逸出字元(escape character)
常見的逸出序列有以下:
1.\n 換行符號
2.\t 水平定位鍵
3.\r 歸位字元
4.\\ 列印反斜線
5.\" 列印雙引號
而電腦儲存字元的方式是以八位元整數
字串
字串顧名思義是一段文字,通常使用一對雙引號將一段文字夾起來,而英文字會佔1Byte,中文字佔2Bytes,而我們要判斷一段文字是否有中文則可以使用
String s="您好";
System.out.println((s.getBytes().length==s.length())?"無中文":"有中文");
利用Bytes總數和字串長度做比對。
2016年6月1日 星期三
粒子群演算法運用及Java程式碼
粒子群主要決策利用「自身經驗」與「其他人經驗」進行決策。
粒子每一次自身經驗都有適應值,可以衡量這次經驗的好壞,
並且有記憶性可以紀錄每次經驗的位置與適應值。
PSO流程圖

PSO表達式
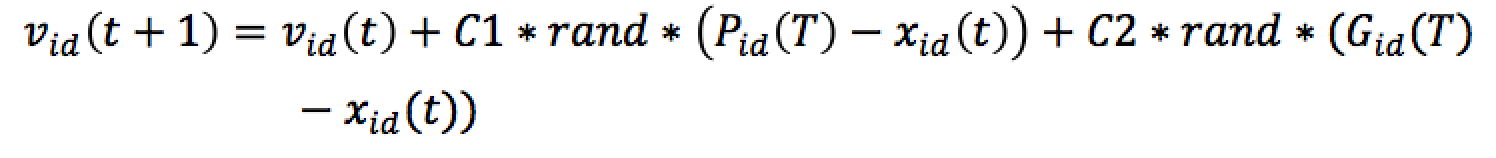
Vid(t):這次粒子的速度
Pid(T):粒子所經過最好的位置(每個粒子都有一個最好位置)
Xid(t):粒子這次的位置
Gid(T):粒子群所經過最好的位置(一個粒子群只會有一個最好位置)
Pid(T):粒子所經過最好的位置(每個粒子都有一個最好位置)
Xid(t):粒子這次的位置
Gid(T):粒子群所經過最好的位置(一個粒子群只會有一個最好位置)
C1,C2:控制且避免數值太大
Xid(t+1):粒子下次的位置
演算法練習:
演算法練習:

1.主要是初始化一開始粒子群Initialization,然後依據繁延代數,進行移動ParticleMove,在這個方法裡我有利用varyVector1、varyVector2來控制,避免數值太大,最後如果數值出過-4~4間,強迫介於在這,不然變化量太大造成位置移動有問題。
2.Parameter沒有使用到封裝,如果需要再自行更改程式碼。
3. 利用JFreeChart free lib , 來畫出JFreeLineChart迭代圖。
2016年5月18日 星期三
Scala IDE for Eclipse 安裝
Help->Install New Software->Add
Name: Scala IDE
Location: http://download.scala-ide.org/sdk/lithium/e44/scala211/stable/site
把 Scala IDE for Eclipse 和 Scala IDE for Eclipse Development Support兩個選項打勾
Name: Scala IDE
Location: http://download.scala-ide.org/sdk/lithium/e44/scala211/stable/site
把 Scala IDE for Eclipse 和 Scala IDE for Eclipse Development Support兩個選項打勾
然後等待一段時間下載
開一個Scala專案
輸入HolloWorld.scala 檔案
object HellWorld extends App {
println ( "hello,")
開一個Scala專案
輸入HolloWorld.scala 檔案
}
執行看看有沒有差
不能使用Application 因為
Application has been deprecated from scala 2.9, probably it has been deleted in scala 2.11 (it still exists in scala 2.10) even though at the moment I can't find proofs for that, use App instead.
執行看看有沒有差
不能使用Application 因為
Application has been deprecated from scala 2.9, probably it has been deleted in scala 2.11 (it still exists in scala 2.10) even though at the moment I can't find proofs for that, use App instead.
2016年5月8日 星期日
基因演算法運用及程式碼
碩士期間剛好有一堂是最佳演算法,講到基因演算法的運用和作業
剛好有機會記下來,與網友們一起討論使用
題目是:

6.挑選與複製方法
7.交配與交配機率
8.突變與突變機率
9.終止條件
1. 題目
Max f (x 1, x2
) = 21.5 + x1 sin(4πx1) + x2 sin(20πx2
)
−3. 0 ≤ x1 ≤ 12.1, 4.1 ≤
x2 ≤ 5.8
試以基因演算法求最大值f
2. 基因演算法(以流程圖或虛擬碼表示即可)
3. 設計編碼方式 (使用二進位編碼來代表 x1 與 x2
的值)
4. 決定群體規模 (族群數量)
5. 設計適應函數 (決定個體適應度的評估標準)
6. 決定挑選與複製方法
7. 定義交配與交配機率
8. 定義突變與突變機率
9. 決定終止條件
10. 結果與討論(含收斂過程圖)
我的解法
2.基因演算法流程圖
我的解法
2.基因演算法流程圖

3.編碼方式
假設某個數值x1=11.1
X1==11.1;
If(x1==11.1)
{
x1=(x1+3)*10;
x1_binary=Integer.toBinary (x1);
x1_binary=Integer.toBinary (x1);
}
x1_binary==10001101;
假設某個數值x1 二進位= 10001101
x1_binary==10001101;
If(x1_binary==10001101)
{
x1=Integer. valueOf(x1_binary);
x1=x1/10-3;
}
X1==11.1;
假設某個數值x1=-3.0
X1==0;
If(x1==-3.0)
{
x1=(x1+3)*10;
x1_binary=Integer.toBinary (x1);
x1_binary=Integer.toBinary (x1);
}x1_binary== 00000000;
假設某個數值x1 二進位= 00000000
x1_binary== 00000000;
If(x1_binary==00000000)
{
x1=Integer.valueOf(x1_binary);
x1=x1/10-3;
}
X1==0;
4.群體規模
(族群數量)
初始群體規模為
int groundCount=10;
經過第一次交配,以後規模擴增為
copulationCount=groundCount*2;
5.適應函數
直接代入
Max f (x1, x2 ) = 21.5 + x1 sin(4πx1) + x2 sin(20πx2 )
求f當適應函數
6.挑選與複製方法
樣本基因利用公式計算出來的各個f值
取出
前10%優秀f樣本基因、前30%優秀樣本基因、前70%優秀樣本基因、前90%優秀樣本基因(輪盤式選擇)
複製完後放入交配池(激增兩倍基因)
7.交配與交配機率
一開始隨機取出兩對基因
把第一對x1前四碼和第二對x2前四碼交配出新基因的x1
把第一對x2前四碼和第二對x1前四碼交配出新基因的x2
強制交配出特定數量
8.突變與突變機率
在交配的時候,有十分之一的機率發生突變,當發生突變的時候,隨機x1或x2發生突變,突變是隨機挑選binary的其中一個做改變。
e.gs., 10001101=>10101101(第三位發生突變)
9.終止條件
其繁延代數跑完,就是終止條件
10.結果與討論
因為我起始基因個數非常的低(設定為10組),所以我依靠演化(交配、突變)來使基因越來越好,但非常依靠繁延代數。
總而言之,每一代的基因都有往好的地方發展出去!所以繁延代數越高,基因品質越好。
以下是程式碼:
以下是程式碼:
訂閱:
意見 (Atom)